
L’usage de données est courant dans le monde journalistique… mais il n’est pas apparu avec internet ! On en retrouve les premières traces dès la fin du 19e siècle, époque à laquelle The Economist publie à la une de sa première édition, le 2 septembre 1843, un tableau de données relatives aux exportations de plusieurs entreprises. A la même époque, le quotidien britannique The Guardian publie un listing dévoilant le nombre d’élèves et le coût de la scolarité dans les écoles de Manchester. Le développement d’outils en ligne pour la visualisation de données, couplée à leur facilité d’utilisation, favorisera toutefois l’émergence de ce que l’on appelle aujourd’hui le journalisme de données. Ce genre journalistique illustre la manière dont des données chiffrées peuvent piloter un récit (et non pas l’illustrer).
De la même manière, la représentation visuelle sous la forme de graphiques n’est non plus pas un phénomène très nouveau. L’histoire de la représentation d’images mentales remonte à l’Antiquité – les Grecs avaient élaboré un système complexe de représentations mentales comme outils de mémoire, les Egyptiens cartographiaient les étoiles. Au Moyen-Âge, l’image comme « substitut du langage » se retrouve dans les vitraux et dans les manuscrits, où les enluminures servaient de point de repère dans le déroulement des textes. Certains manuscrits proposaient déjà une forme de « réalité augmentée » : les pointeurs représentés dans les marges seraient les ancêtres des pointeurs informatiques (flèche et main). D’autres annotations faisant référence à certaines sections du manuscrit se rapportent aux concepts actuels de navigation et d’hyperliens. En 1295, Raymond Lulle (France) préfigure les arbres de la connaissance en proposant un « arbre des vices et des vertus » (aussi appelé arbre des sciences). Un siècle plus tard, en 1370, Nicolas Oresme (France) représentera sous la forme graphique le rapport entre deux variables, préfigurant quant à lui les premiers graphiques en barres. Mais les visualisations de données quantifiées prendront leur essor avec le développement des statistiques, dès la fin du dix-huitième siècle.
Si l’on remonte aux origines de la cartographie, celles-ci sont à trouver dans l’Antiquité. Mais cette pratique – entre art et sciences – s’est surtout développée à partir du 15e siècle. Elle a connu d’importantes évolutions au 19e siècle, avec l’essor de la cartographie statistique. Dans l’Antiquité, les premiers croquis cartographiques avaient pour objectif la conservation de la mémoire des lieux et des itinéraires, et ils étaient gravés sur des tablettes d’argile.
S’il est largement reconnu que nous vivons dans un « déluge de données », ce n’est pas pour autant que celles-ci sont facilement accessibles. Les autorités publiques sont soumises à l’obligation de rendre accessibles toutes les données qu’elles produisent : c’est ce que l’on appelle le phénomène de l’open data. En France, de nombreux portails open data ont essaimé. Les données que l’on va y trouver sont de nature variée : de la liste des urinoirs publics dans une ville donnée à celle des vélos en libre circulation, en passant par les horaires de la RATP, les prénoms les plus attribués dans le pays ou encore les caractéristiques de la population. Les données diffusées sur ces portails ne sont pas toujours complètes et à jour, rendant parfois leur exploitation difficile. Toutefois, elles peuvent constituer un bon point de départ pour un récit, qu’il soit graphique ou cartographique.
Par ailleurs, il existe plusieurs portails open data compilant des données à l’échelle mondiale (Organisation mondiale de la santé, par exemple) ou européenne (Eurostat, par exemple).
Dans le monde du journalisme, il est largement reconnu que les meilleures données, celles qui présenteront le plus de valeur ajoutée, seront celles récoltées par le journaliste lui-même.
Une donnée n’est pas signifiante en elle-même. Elle ne fera sens qu’à partir du moment où elle sera contextualisée et analysée. Toutes les analyses de données sont des interprétations. Ce travail d’analyse n’est pas exempt de subjectivité. De plus, en fonction du point de vue que l’on adopte, il existe plusieurs manières d’interpréter des données. Ce travail d’interprétation peut être faussé par des relations que l’on établit alors qu’elles n’existent pas dans les faits (relations de cause à effet : ce n’est pas parce qu’une population consomme beaucoup de bière et qu’il y est observé un taux élevé de cancer du colon que celui-ci est dû à la consommation de bière). Il peut aussi l’être par les multiples explications pouvant être accordées à un seul et même phénomène. S’agissant de données issues de sondages, la première recommandation est de rester critique : les questions de la taille de l’échantillon et de la marge d’erreur ne sont pas triviales et il est nécessaire de se les poser.
Le concept de qualité des données se réfère à des données fiables, complètes et à jour. Le magazine américain Quartz a établi une liste des problèmes les plus souvent rencontrés par les journalistes… et propose des solutions pour chacun d’entre eux.
Raconter une histoire avec des données n’implique pas nécessairement d’en proposer une visualisation : celle-ci doit être pertinente et apporter de l’information. La visualisation de données a pour objectifs de rendre compréhensible de grandes quantités de données qui ne pourraient pas l’être autrement et, partant, d’en permettre l’analyse.
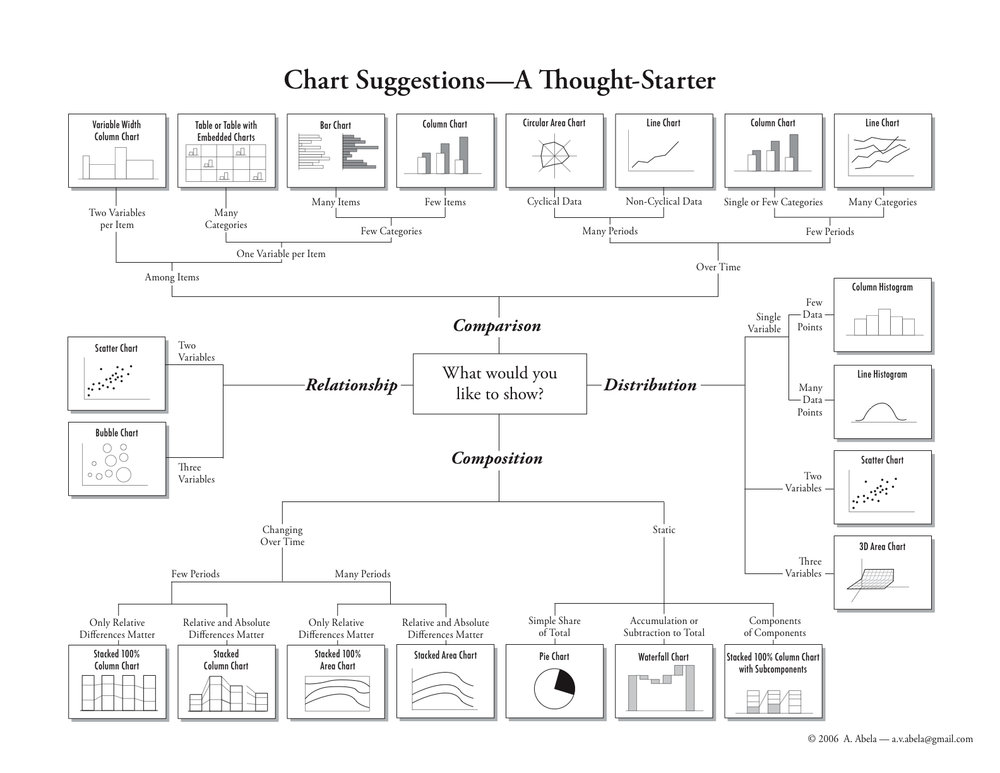
A chaque type de données va correspondre une manière optimale de les représenter. Par exemple, des données qui sont relatives à une évolution dans le temps feront l’objet d’un graphique en courbe. Des données comparant deux variables, par exemple les quantités de pommes et de poires, seront représentées dans des graphiques en barres. La représentation de proportions passera par la création d’un « camembert ». Comment ne pas se tromper et choisir, dans tous les cas, la bonne visualisation ? Le Dataviz Catalog (disponible dans plusieurs langues mais pas encore en français) permet de s’y retrouver parmi les foules de possibilités : https://datavizcatalogue.com/
Si le choix des couleurs concerne l’identité graphique de l’interface, celle-ci porte sur chacun de ses éléments, y compris les infographies et les visualisations de données. Toutefois, certaines règles particulières doivent être observées : les couleurs doivent présenter un degré suffisant de luminosité, elles ne doivent pas obscurcir l’information et être distinguées facilement. Data Color Picker est un outil qui permet de sélectionner une palette de couleurs pour les visualisations de données : https://learnui.design/tools/data-color-picker.html
Les outils présentés ci-dessous présentent l’avantage d’être gratuits et accessibles dans leur utilisation. Ils sont régulièrement utilisés par les journalistes :